
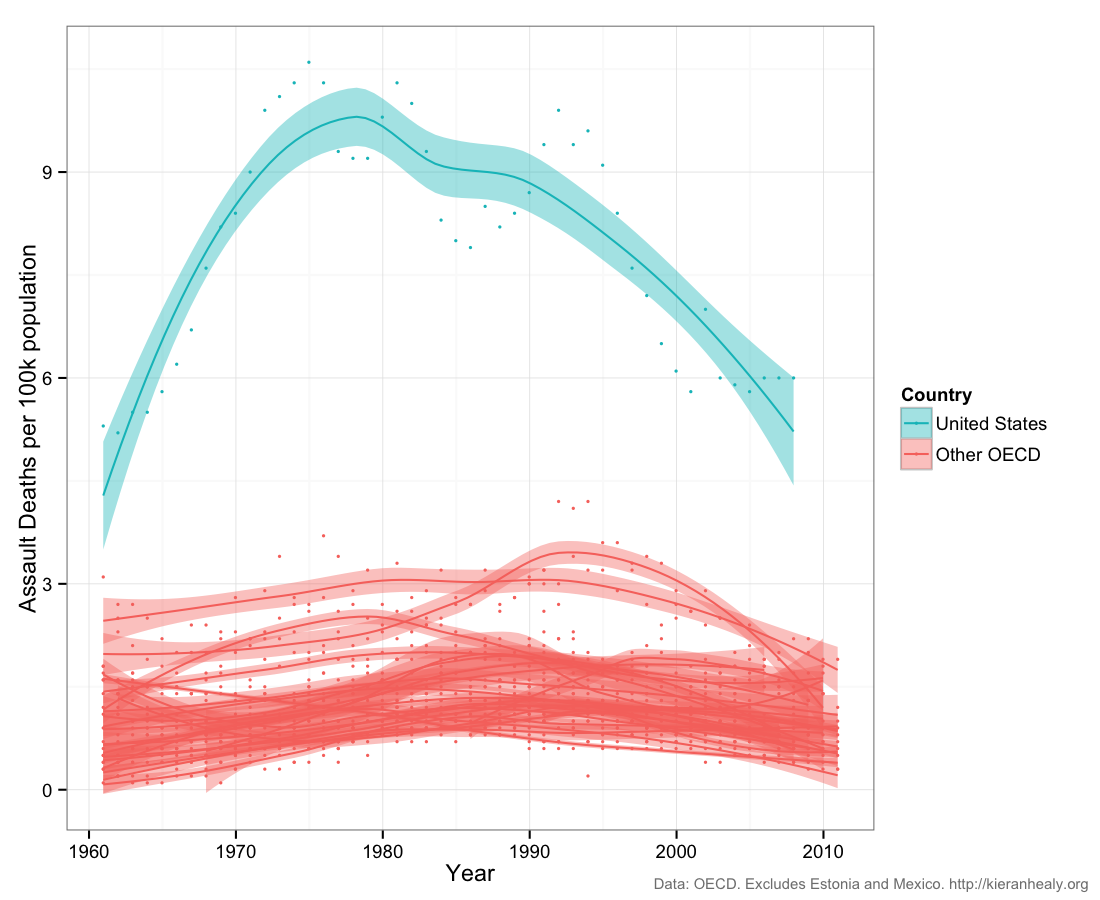
This Saturday is the anniversary of the Sandy Hook School shootings. The figure below (from Kieran Healy) shows that the US has a higher rate of homicides than other OECD countries. Since Sandy Hook, however, the US has done nothing of substance to address its homicide problem.
One reason that nothing has changed may be that the modest gun regulations proposed after Sandy Hook would likely have had only a modest effect on gun deaths.
But in new research, Andrew V. Papachristos and Christopher Wildeman have shown that you can identify likely homicide victims in high crime neighborhoods through an analysis of their social network. This approach would not have predicted the deaths at Sandy Hook, because Adam Lanza wasn’t part of anyone’s network. Nevertheless, this research might be the foundation of an effective approach to preventing some types of homicides. But it frightens me.
Papachristos and Wildeman studied a Chicago neighborhood of 82,000 people. The residents were already at high risk of being murdered (55 homicides per 100,000 / year, compared to 20/100,000 for the rest of the city). They narrowed the sample further to anyone in the neighborhood who was arrested between 2006 and 2011. They then used the arrest data to draw a social network graph by
linking individuals together when they were arrested for the same crime. The basic underlying assumptions are that people who are arrested together (a) know each other and (b) engage in risky behaviors together, in this case, illegal behavior.
They found that
the victims in 41% (N = 103) of all gun homicides in the community are located in this co-offending network. These homicides occur in only 75 of the 1,732 sub-networks, which contain only 3,718 of the 82,000 individuals living in the neighborhood. In other words, 41% of all gun homicides occur in social networks consisting of approximately 4% of the population of the community.
The co-offending network has one large component that connects 3601 people and a host of small networks that do not connect to the large component. Here is what the large component looks like.

The red dots are homicide victims. The ties linking these victims are highlighted by coloring them yellow. Notice that even within this high risk group, murder victims are clustered. Papachristos and Wildeman argue that homicide is like a contagion spreading across the network.
the socially closer one is to a homicide victim—the greater the influence on one’s own victimization. In this sense, homicide is socially contagious and associating with people engaged in risky behaviors—like carrying a firearm and engaging in criminal activities—increases the probability of victimization.
A resident’s network proximity to other murder victims greatly increased the resident’s risk of being murdered.
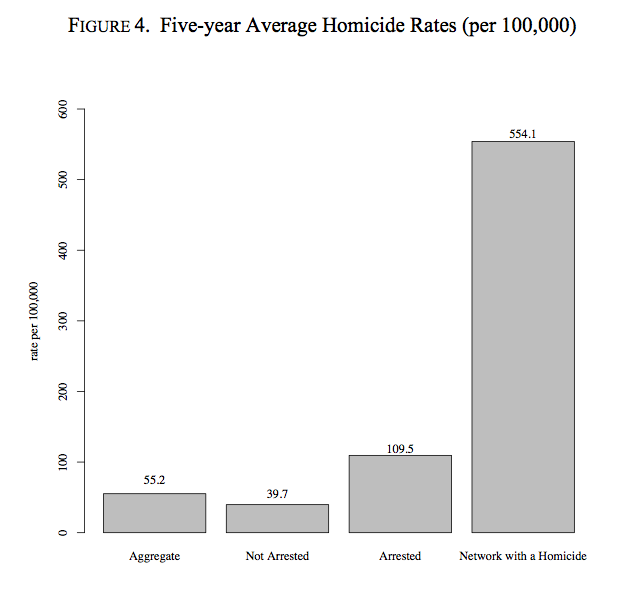
The bar on the left is your risk of being murdered if you live in the neighborhood. The third bar from the left is your risk if you live in the neighborhood and have been arrested in the last five years. The bar on the far right is your risk if you have been arrested and are closely linked to a murder victim. The victimization rate in this group is ten times that of the community members.
Papachristos and Wildeman concluded that
A social network approach suggests that victimization is not simply a function of [traits such as age, race, or gender], but of how people are connected, the structure of the overall network, the types of behaviors occurring in the network, and an individual’s position in the overall structure.
I have some technical concerns about the paper, but let’s set them aside and discuss possible implications for homicide prevention. Papachristos argued in The Washington Post that the way to reduce homicide
is not broad, sweeping policies, such as New York’s “stop and frisk” or mass arrests, but the opposite: highly targeted efforts to reach specific people in specific places, akin to providing clean needles to drug users to prevent the spread of HIV.
Now, it is not immediately clear how you prevent the murders of these high risk persons. The people deeply embedded in the co-offending network surely know they are at risk of being shot. And we are not going to issue them body armor. However, having highly discriminating risk information would allow someone like Harold Pollack to target his violence prevention intervention to those at highest risk.
It’s also possible that network predictions could be used by the police to conduct precisely targeted “stop and frisks.” Instead of indiscriminately stopping any young male person of color, the police might create a watchlist of persons whose location in a criminality network indicates that they are at high risk of being murdered.
We should also think about how network criminology might develop in the future. Papachristos and Wildeman got strong results from arrest records, a surprisingly thin harvest of data. The social graph estimated from co-arrest data is doubtlessly only a weak proxy for the actual criminal network. However, perhaps adding other sources of data could lead to a graph that more closely mirrored the actual social network.
For example, the Chicago police have an extensive system of wireless closed circuit surveillance cameras. High resolution cameras and facial recognition software could allow the police to record the everyday public contacts between neighborhood residents. Gang boundaries constrain residents’ movements, so perhaps gang memberships could be inferred from patterns of movement of residents. If so, co-membership in gangs would be observable and could be added to the network graph. Social network graphs estimated from richer data would likely mirror actual social networks better than co-arrests graphs. These enhanced graphs might predict victimization better than the co-arrest network; leading to yet more closely targeted police interventions.
And then we need to ask: Do we want the police harvesting records and surveillance data to model our social networks? Even if it prevented a significant number of homicides?
TIE authors have written a lot about guns. Here are 1, 2, 3, 4, 5, 6, 7, 8, 9… posts.
