
In a post last week—which you should read if you don’t know what an “instrumental variable” (IV) is—I described the key assumption for a good IV: it’s uncorrelated with any unobservable factor that affects the outcome. “Unobservable” is a term of art. Practically speaking, it actually means anything not controlled for in the system of equations used to produce the IV estimate.
Example: Consider a study of the effect of cardiac catheteriation in heart attack patients on mortality in which the investigators employ the following IV: the difference in distance between (a) each patient’s residence and the nearest hospital that offers cardiac catheterization and (b) each patient’s residence and the nearest hospital of any type. (See McClellan, McNeil, and Newhouse, for example.) Is this differential distance a good instrument? Without controlling for other factors, probably not.
It’s no doubt true that the closer patients live to a hospital offering catheterization relative to the distance to any hospital, the more likely they are to be catheterized. But hospitals that offer catheterization may exist in areas that are disproportionately populated by patients of a certain type (e.g., more urban areas where patients have a different racial mix than elsewhere) and, in particular, of a type that experiences different outcomes than others. To the extent the instrument is correlated with observable patient factors (like race) that affect outcomes, the IV can be saved. One just controls for those factors by including them as regressors in the IV model.
The trouble is, researchers don’t always include the observable factors they should in their IV specifications. For instance, in the above example if race is correlated with differential distance and mortality, leaving it out will bias the estimate of the effect of catheterization on mortality. This is akin to an RCT in which treatment/control assignment is partially determined by a relevant health factor that isn’t controlled for. Bad, bad, bad. (But, this can happen, even in an RCT designed and run by good people.)
In a recent Annals of Internal Medicine paper, Garabedian and colleagues found substantial problems of this type in a large sample of IV studies. They examined 65 IV studies published before 2012 with mortality as an outcome and that used any of the four most common instrument types: facility distance (e.g., differential distance), or practice patterns at the regional, facility, or physician level. Then they scoured the literature to find evidence of confounding for these instruments and categorized the observable factors that, if not controlled for, could invalidate them. Finally, they tabulated the proportion of studies that controlled for various potential confounders. That table is below.
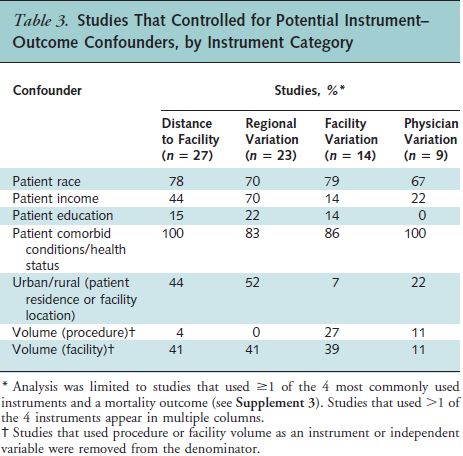
Some confounders, like patient comorbidites, are often included as controls. Others, like education or procedure volume are much less commonly included. This is worrisome. Here are the authors’ final two sentences:
[1] Any instrumental variable analysis that does not control for likely instrument–outcome confounders should be interpreted with caution.
This is excellent advice. I agree.
[2] Although no observational method can completely eliminate confounding, we recommend against treating instrumental variable analysis as a solution to the inherent biases in observational CER [comparative effectiveness research] studies.
My emphasis is added, because this is devastating and, I think, inconsistent with the paper’s contribution. I cannot agree with it. Here’s why:
- It’s one thing to find that many specific IV studies are poorly done, but it’s quite another to suggest IV, in general, should not play a role in addressing bias in observational CER. Indeed, there are many poor studies using any technique. There are bad propensity score studies. There are flawed RCTs. Does that make these inappropriate techniques for CER?
- Let’s consider the alternatives: Propensity scores do not address confounding from unobservables, so they can’t be a complete solution all CER problems. RCTs are impractical in many cases. And even when they’re not, it’s a good idea to do some preliminary observational studies using methods most likely to credibly estimate causal effects. It seems to me we need IVs precisely because of these limitations with other techniques. (And we need the other techniques as well.)
- The authors identified precisely how to do more credible IV studies. Shouldn’t we use that knowledge to do IVs that can better address selection bias instead of concluding we cannot?
- Not every confounder the authors identified need be included in every IV study. Just because a factor might confound doesn’t mean it does confound. This is important because some factors aren’t readily available in research data (e.g., race, income, or education can be missing from the data—in many cases they can be included at an area level, however). To reassure ourselves that no important factors are among the unobservables, one can perform some falsification tests, which are very briefly mentioned by the authors. This validity check deserves far more attention, and is beyond the scope of this post.
The Garabedian paper is a tremendous contribution, an instant classic. I applaud the authors for their excellent and laborious work. Anybody who is serious about IV should read it and heed its advice … right up until the last sentence. It’s possible to do good IV. The paper shows how and then, oddly, walks away from it.
