
In 1998, Ted Kaptchuk (ungated PDF) wrote a nice piece on the history of placebo.
Presuppositions embedded in the new concept of placebo also helped implement new methods of using frequency statistics to make causal inferences. The critical assumption here was that the placebo effect was a monolithic effect which was present to the same degree and same direction in both the treatment and dummy arms. (Anomalies such as placebo with a larger effect than the real drug or a placebo that could reverse pharmacological activity, were conveniently overlooked as was the possibility of verum and placebo being differentially effected by the context of the RCT or of interacting.) For the emerging RCT model, the treatment and dummy arm of trials were assumed to receive equal and independent amounts of this force; one could simply subtract the amount of placebo effect to determine the presence (or absence) of specific drug effect. The possibility that the placebo effect could act differentially in the two arms was discounted. This “assumption of additivity… enable[d] one to infer that the variabilities within the treatments should have a… [random] distribution.” Without the premise of a single placebo effect, commonly used statistical procedures would be confounded.
We often interpret “no better than placebo” as “no effect.” This isn’t correct. It really means, under the assumption described in this quote, “no additional effect beyond that of placebo (which is, itself, often not nothing).”
But, there are even deeper issues, as described by Karin Meissner and colleagues in a systematic review of migraine prevention, which Aaron mentioned in his recent post on The Upshot.
Differential responses to different types of placebo controls would challenge the classic interpretation of randomized clinical trials that the treatment with the greatest specific effect compared with its placebo control is also the most effective one. Rather, a direct comparison of the different types of treatments would be necessary to find out the best treatment option for a certain disease. Otherwise, a complex intervention with a small specific effect but a large placebo effect, for example,would be considered of little value while still being more effective than a simple drug application with a moderate specific effect but only a small placebo effect. This paradox has been termed the efficacy paradox (Figure 1).
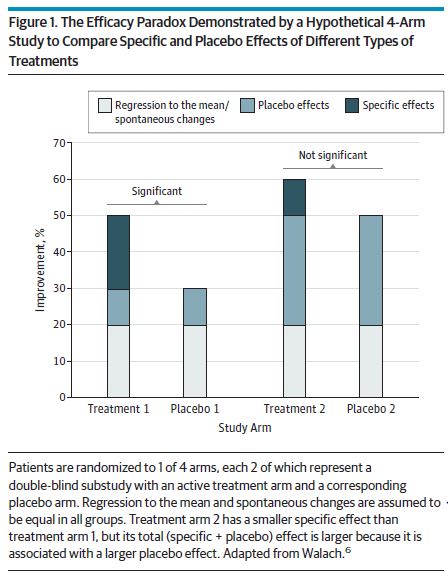
A conclusion of their review was that sham acupuncture and sham surgery were better at preventing migraines than oral drug placebos. Think about that. It’s not just that fake stuff cures, but some modes of delivery of fake stuff cures more than others. I’ll say more about the placebo effect in forthcoming posts.
